
Being able to quickly and safely maintain your instrumented safeguards is essential to maximizing process uptime. Maintenance facilities and procedures should always be factored into front-end loading estimates for instrumented safeguards. However, it is likely that many sites have encountered projects, where provisions for maintenance, test and repair were treated as an afterthought.
The failure rates assumed during the verification of the risk reduction are based on the timely performance of the routine planned preventive maintenance (PPM). The reliability of an instrumented safeguard also depends on the scope and timing of periodic inspections and the timeliness of any needed repair when a fault is detected. Procedures and maintenance facilities can be needed shortly after start-up, as early failures are found and planned maintenance work begins.
An effective plan for instrumented safeguard maintenance can impact:
- equipment and piping – taps, bleeds, valves, maintenance bypass lines, spare parts strategies
- operating strategy – whether to commit to always coming down to safe state for test and repair or alternatively to design for on-line maintenance and repair activities
- organizational plans – need sufficient numbers of competent personnel to execute the activities, capture the relevant performance data, and investigate abnormal behavior
The following case study highlights an incident where there was plenty of evidence that the existing equipment was not performing as needed. A change in the instrument specification was also not carried forward into the maintenance procedures, so the criticality of a maintenance task was unrecognized by the technicians executing the test. Changes in equipment technology often impact maintenance procedures, but if the management of change process does not drive personnel to examine the maintenance procedures, the disconnect between the field and the procedure can have significant safety impact, as illustrated by the Hemel Hempstead incident.
Case Study Example:
Fuel storage; Hemel Hempstead, England; December 11, 2005
Impact: Explosion and fire; 43 injuries; 2,000 evacuated, commercial and residential damage
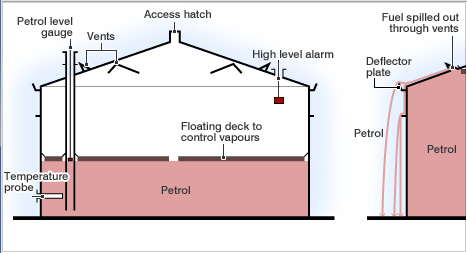
Summary
Gasoline was being delivered to the tank on the day before the incident. Early the next morning, the Automatic Tank Gauging (ATG) system displays an unchanging level, although the tank continued to fill. By practice, the operator controlled level by terminating transfer upon receipt of the user alarm. However, the ‘user’, ‘high’, and ‘high high’ level alarms used the same transmitter, so the failure of the shared transmitter rendered these alarms inoperative. Since the alarm never activated, the operator did not take action to terminate transfer.
An independent high-level switch, set above the ATG high-high level, was designed to close inlet valves and activate an audible alarm, but it also failed. The high level switch had been disabled when the maintenance organization, due to lack of understanding of the relatively new technology and to insufficiently detailed procedures, did not reinstall a lock on the switch test arm. Without the lock, the level switch was not activated when the float was lifted. By late afternoon, the tank overfilled and contents spilled out of tank roof vents. A vapor cloud was formed and noticed by tanker drivers and by people outside the facility. The fire alarm was activated and firewater pumps were started. An explosion occurred a short time later, likely ignited by the startup of the firewater pumps.
Instrumentation and Controls Gaps
- Analog level had 14 dangerous failures (stuck) in preceding 3.5 months
- Safety implications of frequent analog level dangerous failures not noted or logged
- 3 level alarms did not activate due to same analog level failure
- High level switch interlock failed due to undermanaged instrument technology change performed by maintenance group ~18 months earlier
Key Automation Learning Points
It is critical to train maintenance staff to properly test equipment and to verify that the equipment has been properly returned to service. The fault response and repair procedures should include a check for unacceptably high failure rates. Written instructions should be provided on how to escalate these situations to maintenance and facility leadership for investigation and correction.
In the above case, a control instrument with abnormally frequent failures (a maintenance “bad actor”) went unreported. The only independent safeguard failed due to an instrument technology change that was not effectively incorporated into the maintenance program.
Sustainability Actions
- Work checks for abnormal failures and to whom among leadership to escalate this information to should be incorporated into the detailed written maintenance procedures
- A change to make, model, or electronic version number consider the maintenance strategy and ensure that PPM and test procedures are updated and maintenance personnel retrained if needed.
References:
- 2007. Buncefield Standards Task Group (BSTG) Final Report. UK: Health and Safety Executive.
- 2017. Guidelines for Safe Automation in Chemical Processes-2ed. New York: AICHE.
- Summers, Angela E., E. Roche, H Jin, M Carter. 2015. “Incidents That Define Safe Automation.” Presented at 61st International Instrumentation Symposium, Huntsville, Alabama, May.